Thursday, December 31, 2009
Sort a huge file
Wednesday, December 30, 2009
Selecting the median in an array
Tuesday, December 29, 2009
A good tool for POS tagging, Named Entity recognition, and chunking,
Monday, December 28, 2009
Introduction to Computational Advertising : Andrei Broder's course online
In this course we aim to provide an overview of the technology used in building online advertising platforms for various internet advertising formats."
Handsout of Andrei's course on Computatitional Advertising are now on line
Sunday, December 27, 2009
KD-Tree: A C++ and Boost implementation
Here you have the code.
Saturday, December 26, 2009
Xmas present: Machine Learning: An Algorithmic Perspective
Friday, December 25, 2009
MultiArray: a useful container.
MultiArrays can be accessed with the traditional iterator pattern, or accessed with the conventional bracket notation.
Maybe the most useful feature of MultiArray is the possibility to create views, where a subset of the underlying elements in a MultiArray as though it were a separate MultiArray.
Thursday, December 24, 2009
Building an HTTP proxy for filtering content
C++ is a must for any production ready code, such as online search code (and if you use STL and boost you have a rich lib set). C# is useful for offline code, due to the inner rich set of lib set. Some people loves Java for this stuffs (e.g. Lucene, Hadoop, and other very good enviroment). Then, you you are in the scripting coding for fast and dirty prototyping you may want to use python (which is good for strong typed system) or perl (which is good for the vast set of modules, see CPAN).
So, I need to write an HTTP proxy for filtering some content. What is my choice? In this case, perl with HTTP::Proxy module, which allows me to filter both headers and content.
Wednesday, December 23, 2009
A commodity vector space class
PS: getting the sparse version is easy if you use Boost Ublas.
Tuesday, December 22, 2009
Is this... the real 3D Mandelbrot then?
 "The original Mandelbrot is an amazing object that has captured the public's imagination for 30 years with its cascading patterns and hypnotically colorful detail. It's known as a 'fractal' - a type of shape that yields (sometimes elaborate) detail forever, no matter how far you 'zoom' into it (think of the trunk of a tree sprouting branches, which in turn split off into smaller branches, which themselves yield twigs etc.).
"The original Mandelbrot is an amazing object that has captured the public's imagination for 30 years with its cascading patterns and hypnotically colorful detail. It's known as a 'fractal' - a type of shape that yields (sometimes elaborate) detail forever, no matter how far you 'zoom' into it (think of the trunk of a tree sprouting branches, which in turn split off into smaller branches, which themselves yield twigs etc.).It's found by following a relatively simple math formula. But in the end, it's still only 2D and flat - there's no depth, shadows, perspective, or light sourcing. What we have featured in this article is a potential 3D version of the same fractal"
Monday, December 21, 2009
Facebook is growing big .. and I mean REALLY BIG!
Sunday, December 20, 2009
Conditional Random Fields
and labeling sequence data and are a valid alternative to HMMs. CRF++ is a valid package for computing CRF
Saturday, December 19, 2009
Social, Mobile and the Local search
Friday, December 18, 2009
SAT and hill-climbing
Pick a random unsatisfied clauses
Consider 3 moves; flipping each variable
If (any improve the evaluation)
{
accept the best
}
else
{
probability 0.5 : take the least bad
probability 0.5: pick a random move
}
Impressive no? and what this algorithm reminds to you?
Thursday, December 17, 2009
Ellg: an open source social platform
Wednesday, December 16, 2009
Tuesday, December 15, 2009

Monday, December 14, 2009
Neural Networks and backpropagation
Any other suggestions for different update rules?
Sunday, December 13, 2009
CTR and search engines
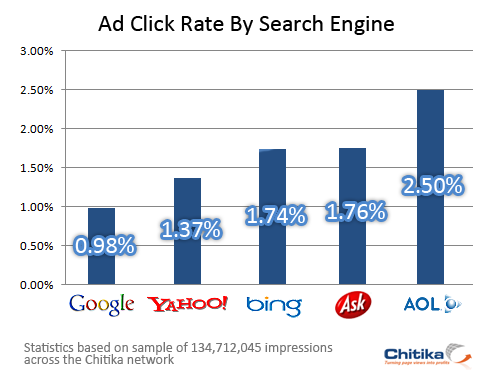 Chitka Research has released a report showing Bing users, the new search engine from Microsoft, clicking on ads 75% more often than Google users.
Chitka Research has released a report showing Bing users, the new search engine from Microsoft, clicking on ads 75% more often than Google users.Good sign? Ask and AOL has more CTR than bing
Saturday, December 12, 2009
Google: a usefult set of slides to build a distributed system
Friday, December 11, 2009
Power Law and an Enrico Fermi's motivation
In this model, particles are produced at constant rate and the particles' distribution at time t is an exponential of the form \lamda * e ^ - (\lamda * t) (in other words there is a negative exponential contribution). In addition, particles gain energy when time is passing such as C e ^ (\alpha * t) (in other words this is giving a positive exponential contribution).
Under these two forces the particles will have a power law density. Can you explain why?
Thursday, December 10, 2009
Google is running fast on News (Please do not forget History)
The key idea is that: "Each story has an evolving summary of current developments as a well as an interactive timeline of critical events. Stories can be explored by themes, significant participants or multimedia."
Google, I do like the idea of a collaboration with NYT and WP. Anyway, the idea of following the evolution of the story is not a new idea. It has been published in a patent Systems and methods for clustering information and used live by Ask.com as the 'History' feature:
"A clustering algorithm is used to cluster the information according to the selected window of time .omega.. New clusters can be periodically linked to chains, or new topic clusters can be identified, periodically. The new clusters are compared to other clusters to discover similarities in topic. When similarities are found among clusters in different time windows, the clusters are linked together to form a chain or are added to a preexisting chain. This comparison with clusters in previous time windows can stop if no similar information is found for a period of time proportional to the extension of the current cluster or to an extension of the chain. The chain of clusters is organized in a hierarchy according to the temporal information of each cluster: the most recent cluster is typically displayed at the top of the chain and the oldest cluster is typically displayed at the bottom of the chain."
On Feb 2008, this article gave a positive judgment about the 'History' feature: "My vote – thumbs up. Ask.com has done well integrating social media with news in a clean, easy-to-use interface. Features like story history could save me time"
Wednesday, December 9, 2009
What are the zettabytes?
"In 2008, Americans consumed information for about 1.3 trillion hours, an average of almost 12 hours per day. Consumption totaled 3.6 zettabytes and 10,845 trillion words, corresponding to 100,500 words and 34 gigabytes for an average person on an average day. A zettabyte is 10 to the 21st power bytes, a million million gigabytes. These estimates are from an analysis of more than 20 different sources of information, from very old (newspapers and books) to very new (portable computer games, satellite radio, and Internet video).
Video sources (moving pictures) dominate bytes of information, with 1.3 zettabytes from television and approximately 2 zettabytes of computer games. If hours or words are used
as the measurement, information sources are more widely distributed, with substantial amounts from radio, Internet browsing, and others. All of our results are estimates.
Previous studies of information have reported much lower quantities. Two previous How Much
Information? studies, by Peter Lyman and Hal Varian in 2000 and 2003, analyzed the quantity of original content created, rather than what was consumed. A more recent study measured consumption, but estimated that only .3 zettabytes were consumed worldwide in 2007.
Hours of information consumption grew at 2.6 percent per year from 1980 to 2008, due to a combination of population growth and increasing hours per capita, from 7.4 to 11.8. More surprising is that information consumption in bytes increased at only 5.4 percent per year. Yet the capacity to process data has been driven by Moore’s Law, rising at least 30 percent per year.
One reason for the slow growth in bytes is that color TV changed little over that period. High-definition TV is increasing the number of bytes in TV programs, but slowly.
The traditional media of radio and TV still dominate our consumption per day, with a total of 60 percent of the hours. In total, more than three-quarters of U.S. households’ information time is spent with noncomputer sources. Despite this, computers have had major effects on some aspects of information consumption. In the past, information consumption was overwhelmingly passive, with telephone being the only interactive medium.
Thanks to computers, a full third of words and more than half of bytes are now received interactively.
Reading, which was in decline due to the growth of television, tripled from 1980 to 2008, because it is theoverwhelmingly preferred way to receive words on the Internet."
Tuesday, December 8, 2009
Google is moving into Real-Time search
Monday, December 7, 2009
Yahoo! and Microsoft cement 10-year search deal
From The Telegraph
"Microsoft’s Bing and Yahoo! search are pooling their efforts in order to try and take on the dominance of Google in the search market. According to Net Applications’ most recent global figures, Google accounted for 85 per cent of all searches, while Bing took 3.3 per cent share and Yahoo! search accounted for 6.22 per cent of the total market. "
Sunday, December 6, 2009
Saturday, December 5, 2009
Dividing a number with no division
"Given a>0 can you compute a^-1 without any division?"
Friday, December 4, 2009
Google Customizes More of Its Search Results
"For many of its users, Google offers Web search results that are customized based on their previous search history and clicks. For example, if someone consistently favors a particular sports site, Google will put that site high in the results when they look up sports topics in its search engine.
But there has always been one catch: people had to be signed in to a Google account to see such customization.
On Friday Google said it was extending these personalized search results to people who are not logged into the service."
Thursday, December 3, 2009
Quoting Wikipedia, which cites me and Alessio
A more recent study, which used Web searches in 75 different languages to sample the Web, determined that there were over 11.5 billion Web pages in the publicly indexable Web as of the end of January 2005.[61]
Wednesday, December 2, 2009
Search capitalization

This is a one year comparison about market capitalization on 1 Dec 2009. I used Apple as benchmark since that tech stock had a great performance this year.
Tuesday, December 1, 2009
Web Search signals
Monday, November 30, 2009
Minimize a quadratic function
Pretty elegant application of Karush–Kuhn–Tucker conditions
Sunday, November 29, 2009
Vivisimo, SnakeT, Ask, Bing and now Google side bar
"Unlike Bing and Yahoo, Google does not have a permanent left hand sidebar with additional links for more narrow searches. Instead there is a link at the top of the page called “Show options”.
Click on it and Google will add a sidebar which helps you refine your search query. You may, for instance, limit your search to new pages from the last hour.
Search Engine Land reports that Google will change it’s search result pages next year and give them a more coherent look and feel.
Most importantly: It seems the sidebar will become a permanent feature on all search result pages.

The sidebar will include links to Images, News, Books, Maps and “More”, as well as related searches and links that let you limit the search to a specific time period.
Google will give you the alternatives (or “modes”) it thinks is most relevant to your search.
Ask.com launched search result pages like this in 2007. Because of this Ask.com became one of our favorite search engines. Ask later abandoned its “3D” search in order to become more like Google!"
Saturday, November 28, 2009
I will give a talk at Online Information 2009
Friday, November 27, 2009
When you want to optimize the monetization...
Thursday, November 26, 2009
Search Layers
1. how do you partition the documents?
2. what is "good"?
3. what is "enough"?
Please formalize your answers.
Wednesday, November 25, 2009
Distribution of Facebook Users (~300M world wide)

Facebook claims that they have more than 300 Million of users world wide. I sampled their ads user database and found the following geographical users' distribution:
- 34.32% are in U.S.
- 8.15% are in U.K.
- 5.05% are in France
- 4.99% are in Canada
- 4.50% are in Italy
- 4.42% are in Indonesia
- 2.65% are in Spain
Tuesday, November 24, 2009
Monday, November 23, 2009
Weights and Scale: a variation.
Sunday, November 22, 2009
Ranking teams
- What is the probability for team i to win on team j?
- What is the probability of the whole season (each team plays against the remaining ones)?
- Find an algorithm to rank the teams
Saturday, November 21, 2009
Random Decision Trees
- Different training sets are generated from the N objects in the original training set, by using a bootstrap procedure which randomly samples the same example multiple times. Each sample generate a different tree and all the trees are seen as a forest;
- The random trees classifier takes the input feature vector, classifies it with every tree in the forest, and outputs the class label that recieved the majority of “votes”.
- Each node of each tree is trained on a random subset of the variables. The size of this set is a training parameter (in general sqrt(#features)). The best split criterium is chosen just considering the random sampled variables;
- Due to the above random selection, some training elements are left out for evaluation. In particular, for each left-out vector, find the the class that has got the majority of votes in the trees and compare it to the ground-truth response.
- Classification error estimate is computed as ratio of number of misclassified left-out vectors to all the vectors in the original data.
Friday, November 20, 2009
Bing UK -- Out Of Beta Tag For Handling Search Overload In The UK
It is true that Internet has drastically grown in the past few years and has become more complex, but Search Engines are still on the verge of evolution. In order to make search engines more reliable information resource for users, Microsoft launched Bing in June, 2009.
Bing was launched under Beta tag in the UK. Microsoft at that time promised to remove the tag only under one condition i.e if its experience would be different from the competition and if the results would be outperforming in terms of UK relevancy.
The Bing team reached its objective on November 12, 2009 and the credit goes to London-based Search Technology Center. Microsoft says that 60 engineers behind the project in Soho have done extensive job at localizing the Bing global experience for the UK users in just 5 months.
Thursday, November 19, 2009
Is this the future of Search?
WOW.
Scaling Internet Search Engines: Methods and Analysis
This technology has been adopted by Fast and later on by Yahoo.
Wednesday, November 18, 2009
Visual Studio and Parallel computation
Tuesday, November 17, 2009
Bing Gains Another Half Point Of Search Share In October
- During October, Bing represented 9.9% of the market, up from 9.4% in September, according to comScore.
- Yahoo got slammed, losing almost a full percentage point of the market, to 18.0%, down from 18.8% in September.
- Google gained a bit of share, to 65.4% in October, up from 64.9% in September.
Total search volume increased 13.2% in October, below 17.3% growth in September.
More information here
Monday, November 16, 2009
Bing - Out Of Beta Tag For Handling Search Overload In The UK
More information here
Sunday, November 15, 2009
A collection of benchmarks for Learning to Rank algorithms
Saturday, November 14, 2009
Directly Optimizing Evaluation Measures in Learning to Rank
"Experimental results show thatthe methods based on direct optimization of evaluation measure scan always outperform conventional methods of Ranking SVM andRankBoost. However, no significant di fference exists among the performances of the direct optimization methods themselves."
In this case, my preference goes to AdaRank for its semplicity and clear understanding of the key intuitions behind it.
Friday, November 13, 2009
A taxonomy of classifiers
- Statistical
- Regression (linear), (logistic)
- Structural
- Rule Based (production rules, decision tree, boosting DT, Random Forest)
- Neural Network
- Support Vector Machine
- Distance Based
- Functional (linear, wavelet)
- Nearest Neighbor (kNN, Learning Vector Quantization, Self-organizing maps)
Classifiers are generally combined in an Ensembles of classifiers. Many of the above methods are implemented in OpenCV
Thursday, November 12, 2009
A collection of public works on Learning to Rank from Microsoft
- RankNet [2005]
- LambdaRank [2006-2009], works directly on optimizing DCG
- BoostTreeRank [2006], ranking as a classification problem and uses boosting
- LamdbaMart [2009], which combines the above with boosting, regression trees and allows to have submodels
Wednesday, November 11, 2009
GO a new language from Google
I am trying to understand a bit more about the language. Garbage collection is there, type inference is there, lamba/closure is there, but where are modern things like generic/collections and exceptions?
Generic is a commonly accepted programming paradigm that any modern programmer is using (C++ has it, Java has it, etc, etc?)
BTW, there was already a programming language called Go and google missed it ?
Tuesday, November 10, 2009
Reoder an array in mimum number of steps
Monday, November 9, 2009
DBSCAN clustering algorithm
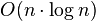 is obtained."
is obtained."Some DBSCAN advantages:
- DBScan does not require you to know the number of clusters in the data a priori, as opposed to k-means.
- DBScan can find arbitrarily shaped clusters.
- DBScan has a notion of noise.
- DBScan requires just two parameters and is mostly insensitive to the ordering of the points in the database
- DBScan needs to materialize the distance matrix for finding the neighbords. It has a complexity of O((n2-n)/2) since only an upper matrix is needed. Within the distance matrix the nearest neighbors can be detected by selecting a tuple with minimums functions over the rows and columns. Databases solve the neighborhood problem with indexes specifically designed for this type of application. For large scale applications, you cannot afford to materialize the distance matrix
- Finding neighbords is an operation based on distance (generally the Euclidean distance) and the algorithm may find the curse of dimensionality problem
Here you have a DBSCAN code implemented in C++, boost and stl
Sunday, November 8, 2009
Invalidating iterators
Saturday, November 7, 2009
A tutorial on static polymorphism
Friday, November 6, 2009
Thursday, November 5, 2009
C++ Polymorphism., static or dynamic inheritance (part II)
- Distance euclidean d
- Distance cosine d
Here the code
Wednesday, November 4, 2009
Tuesday, November 3, 2009
C++ Polymorphism., static or dynamic inheritance
Inheriting is a great thing, but sometime you don't want to pay the overhead of a virtual method. I mean, anytime you overide a method the compiler will add a new entry in the virtual table and at run-time a pointer must be deferenced. When performance is crucial or when you call a method several times in your code you may want to save this cost.
In these situations, Modern C++ programmers prefer to adop a kind of compile-time variant of the strategy pattern. At compile time, the appropriate class and method is called during template instatiation. In this sense, Policy-based design is very useful when you want to save the cost of the virtual table.
In this example, I wrote a distance class and a method distance which is potentially used very frequently by any clustering algorithm. The method can be either a EuclideanDistance, or any kind of different distance. And there is no need of any additional virtual table, every choice is made at compile time statically.
Here you find the code.
Monday, November 2, 2009
Where Google is going with Enterprise, Real time and other stuff
Sunday, November 1, 2009
Can Google Stay on Top of the Web?
1. Microsoft's (MSFT) new Bing search engine picked up 1.5 percentage points of market share in August to hit 9.5%, according to market researcher Hitwise, while Google's share fell from 71.4% to 70.2%.
2. But longer term, Twitter, Facebook, and related services may pose a more fundamental threat to Google: a new center of the Internet universe outside of search. Twitter, now with 55 million monthly visitors, and Facebook, with 300 million, hint at an emerging Web in which people don't merely read or watch material but communicate, collaborate with colleagues, and otherwise get things done using online services.
3. Meanwhile, Google's very success and size are starting to work against it. In the past year the company has been the target of three U.S. antitrust inquiries and one in Italy. Most recently the Justice Dept. on Sept. 18 said Google's controversial settlement with authors and publishers, which would have allowed it to scan and sell certain books, must be changed to avoid breaking antitrust laws. Even Google's own paying customers—advertisers and ad agencies—say they're eager for alternatives to blunt Google's power. Says Roger Barnette, president of search marketing firm SearchIgnite: "People want a No. 2 that has heft and scale."
4. Most of the search quality group's contributions are less visible because its work is focused mostly on the underlying algorithms, the mathematical formulas that determine which results appear in response to a particular query. Google conducts some 5,000 experiments annually on those formulas and makes up to 500 changes a year
Friday, October 30, 2009
How do you evaluate a search engine performance?
Thursday, October 29, 2009
a Facebook Fan Page for any site on the web?
 , laid out the Open Graph as essentially a Facebook Fan Page for any site on the web. So you can imagine that you might be able to create a Facebook-style Wall to include on your site, but able to update your statuses from your site, leave comments, like items, etc. Again, it’s like a Facebook Page, but it would be on your site. And you can only include elements you want, and leave out others."
, laid out the Open Graph as essentially a Facebook Fan Page for any site on the web. So you can imagine that you might be able to create a Facebook-style Wall to include on your site, but able to update your statuses from your site, leave comments, like items, etc. Again, it’s like a Facebook Page, but it would be on your site. And you can only include elements you want, and leave out others."
Wednesday, October 28, 2009
Twitter Growth (by the way of Alessio)
"According to my most recent studies Twitter currently receives about 26 Million tweets per day. It is impressive, especially if you consider that in January 2009 they were hovering around “only” 2.4 Million daily tweets!"
Alessio is the Director of Search @ OneRiot. See my previous posting.
Tuesday, October 27, 2009
Yahoo goes real time with Oneriot
"Techcrunch said Tuesday that Yahoo is planning to partner with OneRiot, which operates a real-time search engine and develops browser add-ons that do pretty much the same thing. The possible deal comes on the heels of separate plans announced by Microsoft and Google last week to integrate Twitter pages into their search results."
Sunday, October 25, 2009
Similarities: what is better?
What is the best one?
It depends. Anyway cosine similarity has a very good behaviour in a large scale experiment run by Google in the paper "Evaluating Similarity Measures: A Large-Scale Study in the Orkut Social Network". Other measures were evaluated such as L1-norm, Pointwise Mutual Information, Pointwise Mutual Infomation with negative feedback, TF*IDF, LogOdds. Dataset for the experiment is Orkut and 4,106,050 community pages with recommendations were considered. Cosine measure was the best one in terms of finding correct correlations between recommendations. I am pretty sure that different measures can have different performances for other datasets. Anyway, this is another example of why I love to KISS.
Keep it simple baby, KISS.
Saturday, October 24, 2009
Starting to be interested to AD Research
Friday, October 23, 2009
Yahoo: Carl Icahn Says His Work Is Done, Resigns From Yahoo’s Board
"It’s hard to determine whether Icahn is throwing in the towel on Bartz or this is actually a vote of confidence. If he really believes in where Bartz can take the company after the search deal is done, then you’d think he’d keep his board seat to have a stronger influence on the company’s direction. But Icahn has always been a transaction-oriented investor. He tries to push companies to do things that will move the stock in a big way, and then he takes his profits and he leaves."
Thursday, October 22, 2009
Twitter: anyone wants to have it.
Web was open in the past: you go out of there and you crawl the public content.
Is not longer like it was used to be: Facebook and Twitter are the faster growing part of the Web and their content is not public. They don't need to make it public to attract traffic from search engines, like traditional online newspapers.
So they keep their content private and they sell it. Is this good for the community? I don't think so. Is this good for Facebook and Twitter investors? Very Very much.
Wednesday, October 21, 2009
Facebook numbers, quite impressive I say
How impressive? Schroepfer threw out some huge numbers. Among them:
- Users spend 8 billion minutes online everyday using Facebook
- There are some 2 billion pieces of content shared every week on the service
- Users upload 2 billion photos each month
- There are over 20 billion photos now on Facebook
- During peak times, Facebook serves 1.2 million photos a second
- Yesterday alone, Facebook served 5 billion API calls
- There are 1.2 million users for every engineer at Facebook
nahhhh
Tuesday, October 20, 2009
Little game to make your friends wonder you are a wizard
Monday, October 19, 2009
Cutting pancakes..
Sunday, October 18, 2009
Do you need a search book but you don't want to bother with so much math?
- evaluatation: precision, recall, F1, and ROC curves;
- ranking: PageRank; DocRank; ClickThrough ranking.
- classification: Naive Bayes, neural networks; decision trees, Bagging; Boosting, etc
- collaborative filtering; recommendations;
- clustering: k-means, ROCK, DBSCAN
Saturday, October 17, 2009
Monday, October 12, 2009
Random walks for species multiple coextinctions
Sunday, October 11, 2009
Puzzle game with dice
Saturday, October 10, 2009
C++ check list
- operator or non operator
- free or class memeber
- virtual or non virtual
- pure virtual or virtual
- static or non static
- const or non-const
- public, protected, private
- return by value, pointer, const pointer, reference, const reference
- return const or non const
- passing by value, pointer, reference
- passing const or non const
- private, public, implicit, explicit constructor
- private, public, implicit, explicit copy operator
- virtual , non virtual destructor
Friday, October 9, 2009
50 Years of C++
Thursday, October 8, 2009
Top world-wide universities
Wednesday, October 7, 2009
DailyBeast and the power of good business deals
DailyBeast received another wonderful prize. That is not just because there is some good technology behind it. That is mostly because they know what is News and they are focused in that business. I believe that technology is neutral and the focus must come from business deals.
Congrats, Tina
very much deserved.
Tuesday, October 6, 2009
Well, you can't do this... Google vs Ask.com
Monday, October 5, 2009
Web Random Bits:
1. What about using a Randomness extractor starting and considering Twitter search as an (high-entrophy) source. There are applications like this based on RF-noise, Lavalamp, and similar funny sources. I would adopt either MD5 or SHA-1 hash function. This will give all the benefits of the crypto-hash function and bias-reduction.
2. Synching is a bit more hard, since the query is not enough. Time is another important factor: the results you see at time t are potentially different from the ones seen at time t + \eps. The index can change and the load balance mechanism in search can bring you to a different search cluster. I guess you must relay on some proxy which must capture a snapshot of twitter and then you must syncronize on the query and the time. There are a couple of services like this out of there.
Sunday, October 4, 2009
CopyCat:: Web Random Bits
"We often need random bits. People toss a coin or use noise from transistors or whatever to obtain random bits in reality. Here are two tasks.
- Devise a method to get random bits from the web. The procedure should not use network phenomenon such as round trip delay time to random hosts etc, but rather should be at application level. Likewise, the procedure should not be to go to a website which tosses coins for you. Rather, it should use some existing web phenomenon or content. Btw, quantifying/discussing potential biases will be nice.
- Devise a method for two people to coordinate and get public random bits from the web. The method can't assume that two people going to a website simultaneously will see identical content or be able to synchronize perfectly.
Saturday, October 3, 2009
Tweetmeme provides a stat service on Twitter
- Click-through data
- Retweet data
- Trees of retweet reach
- Potential visibility
- Influential users
- Tweet Locations
- Referring domains
- User stats
Friday, October 2, 2009
Yummy chocolate table
Thursday, October 1, 2009
Optimization: what is the largest rectangle you can inscribe in a circle
Wednesday, September 30, 2009
Ebay: online auctions is about search and viceversa
Tuesday, September 29, 2009
Google as borg?
searchnewz
Great feedback on some contribute gave to the open source coding community
Cheers!
DJ
http://codingplayground.blogspot.com/2009/01/design-patterns-c-full-collection-of.html
Monday, September 28, 2009
Findory: an old post, I like to propagate it.
Tuesday, September 22, 2009
Tricky puzzle
1. What is the probability to win for John?
2. Is there any strategy better than break-even?
Monday, September 21, 2009
c++ giving an order in the allocating static objects
- How can you guarantee that an object is allocated before another one?
- What if you need to give an order in the de-allocation process of static objects?
Sunday, September 20, 2009
c++ Insulation (IV)
Let's see other situations where you can have dependencies.
- default arguments. If you use default arguments in your method, and then you decide to change them your clients will be forced to recompile.
- enumerations. If you put your enumerations in your .cpp file they are hidden from the client. If you put your enumerations in your .h file, you will introduce a dependency
Saturday, September 19, 2009
A probabilistic model for retrospective news event detection
Friday, September 18, 2009
c++ Insulation (III)
- Inline methods. Inlining is an easy yet powerful way of improving C++ performance. The problem is that if you inline a method than you client will replace its call to your method with the body of method itself. This means you introduce a very strong dependency on you; and your client will see its size increasing a lot. There is cost to pay for it. Just be sure of who is your bed and don't accept people you just met.
- Private members. Ok this is very nasty at first glance. I tell you in one shot: If you declare some private member, and someone is inheriting from you, that guy has a dependency on you. This is very counter-intuitive, I know. You may think. That is private, how it comes that he knows something about my private life. My good friend Giovanni (a real C++ guru) once told me. Private is about access, not about knowledge. You see it, but you are not allowed to access it. A stellar story. Augh Giovanni, you make my day. So you have a dependecy on it. My question: how do you avoid it? What is the cost of your choice?
Addendum: can you identify other reasons why insulation is good and dependencies are bad?
Thursday, September 17, 2009
c++ Insulation (II)
- HasA/HoldsA: if you embedd a pointer or a reference to an object you don't need to know the physical layout of that object. There is no dependency apart from the name of the object itself. So you can make a forward declaration. No more dependency, no more cats to follow. I like cats; I don't like having them come to me just for milk ;-). In the below code fragment, you don't need to include any .h file for including the declaration of B class. no dependecy at all.
class B;
class A {
B * pBobj;
B & rBobj;
};
Wednesday, September 16, 2009
c++ Insulation (I)
Basically, insulation is a way to reduce dependencies in code at compile time (my own pratical definition). What's bad with dependencies? Well, when you have a dependency you basically introduce some additional time to compile the unit on which you depend to. So, you can say: hey wait a minute if I depend on that piece of code this is meaning that I need that code. In C++ this is not always the case. There are some (implict) dependencies that you may want to avoid and you may want to be aware of. If you apply these suggestions, then your coding style will improve a lot. Let's see some of them:
- Include files. Whenever you include a .h, you depend on that code. Ok, Ok you say: if I include it, I need it. Sure; but what about including other .h files in your .c file? Why what you included should, in turn, be included by whatever is including your .h file? stop uncessary dependencies and be fair stella;
- Inheritance. Books say any good OO sytem should leverage inheritance. I say don't believe the hype. Use inheritance with care. In a lot of situations Generics and templates are more efficient. BTW, when you inherit from a class, then you introduce a dependency on it. Sometimes you need, sometime you don't. Just be aware. Anything has a cost. Don't go in that direction without following your brain, and just listening to your heart;
- Layering. When your class (HasA) another user-defined type, you have a dependency on it. Again: hey, if I embedd that object this means that I need it. Correct. So what can you do to avoid it?
Tuesday, September 15, 2009
Monday, September 14, 2009
Microsoft Bing going Visual

Give it a try.
"Until now, I really hadn’t had much reason to switch to its Bing decision engine, which launched back in May, for my Web searching needs. Google was doing just fine. For a while, I was making an effort to use Yahoo but Google somehow always became the default.", ZDNET
Friday, September 11, 2009
Predicting query trends
"Specifically, we have used a simple forecasting model that learns basic seasonality and general trend. For each trends sequence of interest, we take a point in time, t, which is about a year back, compute a one year forecasting for t based on historical data available at time t, and compare it to the actual trends sequence that occurs since time t. The error between the forecasting trends and the actual trends characterizes the predictability level of a sequence, and when the error is smaller than a pre-defined threshold, we denote the trends query as predictable."
This is a more approach that you can use in many contexts. For instance, I have seen it used for understand the coverage and the precision of firing a vertical result time based (such as news, blogs, twitter) into the SERP.
Another observation about the paper. You can better predict wether a query has a predictable trend, by enriching your Querylog with other temporal based data such as Twitter, News and blogs.
Tuesday, September 8, 2009
Data is the king, not algorithms
If you wan to improve the search quality, quite often you need more data to analyze and you do not necessarly need a better algorithm. The best situation is when you are able to "contaminate" or to "enrich" you data with other information coming from different domains.
So you are working on Web search quality, maybe you can get a huge help from other domains such as News, blogs, Dns, Images, videos, etc. You can use these additional data sources to extract signals used to improve the Web search itself.
In many situation, a more sophisticate algorithm will not provide the same impact of some additional data source.
Tuesday, September 1, 2009
Search stats, how the search market is growing.
"Google Inc. saw its share of the worldwide search market grow 58% in July compared to the same month last year, while Yahoo Inc. saw only slight growth and Microsoft Corp. saw its own share increase 41%, according to data published Monday by comScore Inc."
Monday, August 31, 2009
Free the H-1Bs, Free the Economy
I agree.
Sunday, August 30, 2009
Saturday, August 29, 2009
I joined the Bing Microsoft new Search Technology Centre (STC) in Europe
My office is in the London site of STC Europe which is located close to Carnaby Street, right in the centre of Soho a location full of artists, music, and creativeness. The environment and all the people around are having a galvanizing effect on me. I can feel the energy and new ideas flooding.
STC Europe has three sites: London, Munich and Paris. In addition, it has a strong connection with STC Asia in Beijing, the India Development Center, the new in-development STC center at Silicon Valley, and, obviously, the headquarters in Redmond. All in all, this gives me more opportunity to travel, work with smart people, and improve my skills.
After a week here, I like the environment open to experiment with new stuff. You simply say hey I have this new idea for search and you get the resources to experiment with it. If it works, it goes online. Search is all about continuous improvements and evolutions, isnt’it?
Friday, August 28, 2009
The Daily Beast -- Five who are changing the face of the Internet.
I am proud of the ex-group that I led when I was in Ask.com. They contribuited to deliver the News Search algorithmic experience for Dailybeast, together with the other R&D center in NJ (if you search on DailyBeast this is a service powered by Ask.com).
Wednesday, August 26, 2009
Pointers and Smart Pointers
If you are into C++, then you must use smart pointers. Smart pointers are all about resource management. You want to be on the wild but safe side of life. So when you allocate something, you may want to be sure that it will be deallocated at the right time. Talking about sustainability.
It's easy: a smart pointer destructor takes the responsability of freing memory. Now, since the destructor is automatically called by the language when the object goes out of the scope.. you are on the wild but safe side of the life. It's all about RAII.
There are a bunch of smart pointers and you should know them all.
- std::auto_ptr and boost::scoped_ptr. Here the destructor will actually free the memory for you.
- boost::shared_ptr. Here the destrucor will decrement a reference count and when it gets zero counts then it will free the memory. Very useful if you have a share resource, and you are on the wild and open side.
Tuesday, August 25, 2009
Monday, August 24, 2009
Book review: Large Scale C++ Software design
On the negative side, the book is too redundant and could have been reduced. The most interesting Chapter is number 5. Go directly there and start reading from that point.
Sunday, August 23, 2009

Saturday, August 22, 2009
Remember Cuil? Now It’s a Real-Time Search Engine
"Okay, so is this a competitor to Twitter Search? Maybe a little, but really it’s more like OneRiot in terms of real-time search. And to be honest, OneRiot blows Cuil out of the water in this vertical."
Thursday, August 20, 2009
I no longer work for Ask.com
More thant 4 years ago, I started with a small team of people soon expanded into the first Ask.com European R&D Center. Pisa has been selected as location for the excellent quality of life and for the good concentration of software engineers and academic researchers. Our office was magnificent, as you can see from this collection of pictures (1, 2, 3).
Different Pisa teams worked on various projects:
- Image Search, co-lead -- "Ask new image search is a step ahead in a notoriously tricky area. With the quality of its image search results, combined with the new Zoom query refinement feature, I'll be using it as my default image search service going forward", SearchEngineWatch
- News and Blog search, co-lead -- "Ask.com has a pretty original approach to the old-time, old-school, traditional maybe, view of news.", Techcrunch
- Video News Search, lead -- "it's interesting that they've managed to integrate the video playing right into the main page since I doubt all the source videos are the same format (Flash, aspx, etc.)", Niraj user comment
- DailyBeast, Tina Brown's news site, co-lead -- "How did IAC/Tina Brown's new Daily Beast do in its first month? Pretty well: The company says it attracted 2.3 million unique monthly visitors and served up 11.4 million page views. A great start for any publishing startup, Alleyinsider.
- Core Web Search Infrastructure; Pisa was involved in the design and implementation of the middleware software providing the base of all the Ask.com search products. A number of people in Pisa worked on this project.
- RealTime Fresh Web Ranking, lead; injecting and ranking fresh news, video and blogs into Web search results in realtime.
- Frontend Platform for UK, Pisa was involved in the Jeeves rebranding in UK. A number of people in Pisa worked on this project.
- A bunch of Search Patents, "Ask.com has been working hard since then at making itself a more useful resource for timely news information, and has started incorporating multimedia into that mix.", Seobythesea
I posted different blogs pointing out some differentiating aspects of our technology:
- Real Time Query Expansion -- Query Logs vs News
- Fresh Correlations, a valid data source
- What is the status of swine flu?
- What is happening in Washington ? real time text a...
- Fresh Correlations: Valentino Rossi and Jorge Lore...
- Fiat , Chrysler deal done: news, video, blog and i...
- Real Time Gossip: Susan Boyle
- Fresh answers and old ones
- Real time Semantic Search
- American Idol: Freshness, Variety and UI
I want to thank Pisa team for the impressive work we carried out together. I also want to thank all the people from other offices world wide (Edison, NJ ; Oakland & Campbell, CA; London, UK; Dublin, Ireland; Hangzhou, China). In no particular order: Kelly, Jim
I am fortunate to have worked with many bright, talented teams. I learned a lot from them.
Wednesday, August 19, 2009
Tuesday, August 18, 2009
Off-Topic: Ryanair business model
Monday, August 17, 2009
Sunday, August 16, 2009
What Apple is doing with this big-ass data center?
Saturday, August 15, 2009
Google loosing shares
"Numbers released by Nielsen tell a similar story: while Google grew from June to July, it still lost market share to its competitors – from 66.1% in June to 64.8% in July, a 1.3 percentage point drop. However, a closer look at the numbers reveals that Bing wasn’t the primary culprit – it was Yahoo which stole Google’s market share."
Friday, August 14, 2009
Latent Space Domain Transfer between High Dimensional Overlapping Distributions
Tuesday, August 11, 2009
Knol: is not looking goog(d)
quoting marketpilgrim: "It’s been a little over a year since Google launched Google Knol. Now it appears the service may not make it to its 2nd birthday."
Monday, August 10, 2009
How do you define a query session?
What I don't like is the experimental part. A site with 1,5K unique users and 5K pages cannot be considered a Large Web site...
Sunday, August 9, 2009
Book Review: Building Search Application
Building Search Applications: Lucene, LingPipe, and Gate is a pretty good introduction to Information Retrieval with a lot of pragmatic examples. Based on Lucene, Gate and LingPipe. I recomend to add it to your library if you like Lucene and Nutch or if you need to maintain or create a medium scale search application.
Saturday, August 8, 2009
Friday, August 7, 2009
Real Time Query Expansion -- Query Logs vs News (update)
Both of them have a "trending topic", not related to the particular query submitted by the user


Thursday, August 6, 2009
Real Time Query Expansion -- Query Logs vs News
The query log based approach shows its limit when you deal with real time events. In this case, there might be no time to accumulate past queries since events are happening right now. For dealing with real time search query expansion, a new idea is to extract fresh correlation from news events.
For instance, Sonia Sotomayor has been just confirmed to the high court.

Judd Gregg, is one of the supporters

And the algorithm nailed the correlation

Now compare the query suggestion provided by Google, where no correlations are provided since the event is too recent.

And compare with the query suggestion provided by Bing, where related search query log based are shown

I believe that leveraging both past query logs and real time news events can provided a more complete and updated query expansion service, since you leverage the best of both the worlds.

(PS: In addition, please note that both Bing and Ask are showing a related fresh video, while Google is not)