Saturday, December 27, 2014
Saturday, November 8, 2014
Antonio Gulli and Machine Learning
These are some of the visual results of my previous experience in Machine Learning
Use of Machine Learning to build Bing Autosuggest

Use of Machine Learning for integration with facebook

Use of Machine Learning to build Bing News engine

Use of Machine Learning to build Ask.com Universal Results



![]()
Use of Machine Learning to build Bing Autosuggest
Use of Machine Learning for integration with facebook
Use of Machine Learning to build Bing News engine
Use of Machine Learning to build Ask.com Universal Results
Use of Machine Learning to build TheDailyBeast
The use of Machine Learning to detect image similarities (AKA Andy Warhol's period)
Monday, September 22, 2014
Saturday, September 20, 2014
Hands on big data - Crash Course on Spark - Start 6 nodes cluster - lesson 9
One easy way to start a cluster is to leverage those created by Amplab

After creating the keywords for AWS, I created the cluster but had to add -w 600 for timeout
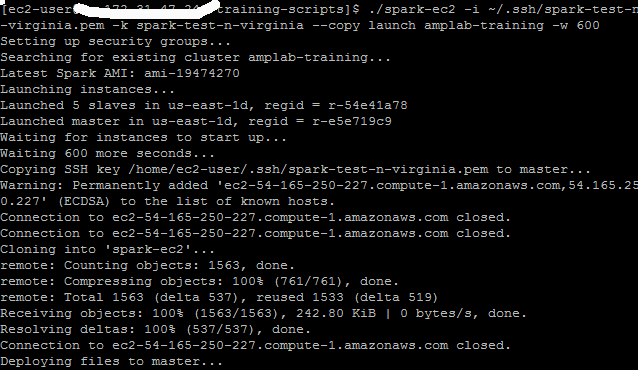
Deploy (about 30mins including all the data copy)
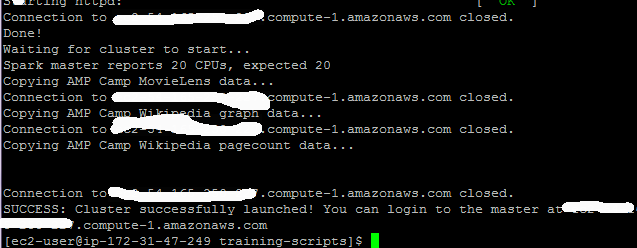
Login

Run the interactive scala shell which will connect to the master

Run commands
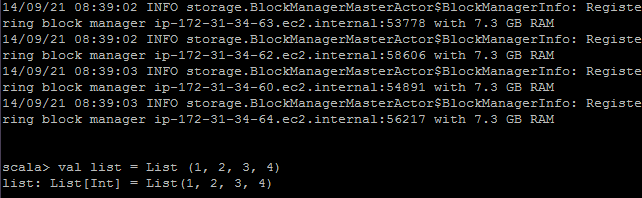
Instances on AWS

Friday, September 19, 2014
Hands on big data - Crash Course on Spark - PageRank - lesson 8
Let's compute PageRank. Below you will find the definition.
Assuming to have a pairRDD of (url, neighbors) and (url, rank) where the rank is initialized as a vector of 1s, or uniformly random. Then for a fixed number of iterations (or until the rank is not changing significantly between two consecutive iterations)

we join links and ranks forming (url, (links, rank)) for assigning to a flatMap based on the dest. Then we reduceByKey on the destination using + as reduction. The result is computed as 0.15 + 0.85 * computed rank
.png)
The problem is that each join needs a full shuffle over the network. So a way to reduced the overhead in computation is partition with an HashPartitioner in this case on 8 partitions
.png) And avoid the shuffle
And avoid the shuffle
.png)

.png)
And compute the PageRank

Other dataset are here
https://snap.stanford.edu/data/web-Google.html
Assuming to have a pairRDD of (url, neighbors) and (url, rank) where the rank is initialized as a vector of 1s, or uniformly random. Then for a fixed number of iterations (or until the rank is not changing significantly between two consecutive iterations)
we join links and ranks forming (url, (links, rank)) for assigning to a flatMap based on the dest. Then we reduceByKey on the destination using + as reduction. The result is computed as 0.15 + 0.85 * computed rank
The problem is that each join needs a full shuffle over the network. So a way to reduced the overhead in computation is partition with an HashPartitioner in this case on 8 partitions
However, one can directly use the SparkPageRank code distributed with Spark
Here I take a toy dataset
And compute the PageRank
Other dataset are here
https://snap.stanford.edu/data/web-Google.html
Thursday, September 18, 2014
.png)
Wednesday, September 17, 2014
Hands on big data - Crash Course on Spark Cache & Master - lesson 6
Two very important aspects for Spark are the use of caching in memory for avoiding re-computations and the possibility to connect a master from the spark-shell
Caching
Caching is pretty simple. Just use .persist() at the end of the desired computation. There are also option to persist an computation on disk or to replicate among multiple nodes. There is also the option to persist objects in in-Memory shared file-systems such as Tachyon.
Connect a master
There are two ways for connecting a master
Caching
Caching is pretty simple. Just use .persist() at the end of the desired computation. There are also option to persist an computation on disk or to replicate among multiple nodes. There is also the option to persist objects in in-Memory shared file-systems such as Tachyon.
Connect a master
There are two ways for connecting a master
val conf = new SparkConf().setAppName(appName).setMaster(master)
new SparkContext(conf)$ ./bin/spark-shell --master local[8]Tuesday, September 16, 2014
Hands on big data - Crash Course on Spark - Word count - lesson 5
Let's do simple exercise of word count. Spark will automatically parallelize the code
.png)
1. Load the bible
2. create a flatMap where every line is put in correspondence with words
3. Map the words to tuples (words, counter where counter is simple starting with 1
4. Reduce by keys, where the reduce operation is just +
.png)
Pretty simple, isn't it?
1. Load the bible
2. create a flatMap where every line is put in correspondence with words
3. Map the words to tuples (words, counter where counter is simple starting with 1
4. Reduce by keys, where the reduce operation is just +
Pretty simple, isn't it?
Monday, September 15, 2014
Hands on big data - Crash Course on Spark - Optimizing Transformations - lesson 4

1. Take a list of names
2. Create buckets by initials
3. Group by keys
4. Map each each initial into the set of names, get the size
5. Collect the results into the master as an array
This code is not super-optimized. For instance, we might want to force the number of partitions - the default is 64Mb chunks


or better count the unique names with a reduceByKey where the reduce function is the sum

Found this example very instructive [Deep Dive : Spark internals], however you should add some string sanity check
.png)
and make sure that you don't run in some heap problems if you fix the partitions
.png)
.png)
You will find more transformatios here
Sunday, September 14, 2014
Hands on big data - Crash Course on Spark Map & Reduce and other Transformations - lesson 3
Second lesson.
- Let's start to load some data into the Spark Context sc (this is a predefined object, storing RDD)
- Then do a map&reduce. Pretty simple using scala functional notation. We map the pages s into their length, and then reduce with a lamda function which sums two elements. That's it: we have the total length of the pages. Spark will allocate the optimal number of mappers and reducers on your behalf. However, if you prefer this can be tuned manually.
- If we use map(s => 1) then we can compute the total number of pages
- If we want to sort the pages alphabetically then we can use sortByKey() and collect() the results into the master as an Array

As you see this is way easier than plain vanilla Hadoop. We will play with other tranformations during next lessons
Saturday, September 13, 2014
Hands on big data - Crash Course on Scala and Spark - lesson 2
Let's do some functional programming in Spark. First download a pre-compiled binary

Launch the scala shell

Ready to go

Let's warm-up, playing with types, functions, and a bit of lamda.
 We also have the SparkContext . Dowloaded some dataset (here wiki pagescounts)
We also have the SparkContext . Dowloaded some dataset (here wiki pagescounts)
 load the data in spark RDD
load the data in spark RDD
 And let's do some computation
And let's do some computation

Launch the scala shell
Ready to go
Let's warm-up, playing with types, functions, and a bit of lamda.
Bigdata is nothing new
How many of those catchy words do you know?
PVM, MPI, NOW, GRID, SKELETON, WAMM
PVM, MPI, NOW, GRID, SKELETON, WAMM
Thursday, September 11, 2014
Hands-on big data - fire a spark cluster on Amazon AWS in 7 minutes - lesson 1
After login in aws.amazon.com, launch the management console

And select EC2

Then, launch an instance

For beginning, a good option is to get a free machine

Select the first one
.png)
Select all the default options and launch the machine. Remember to create the key par

Download the keys
Get putty and puttygen . Launch puttygen load the spark-test.pem and save the private key (it’s ok to have it with no password now)

Check the launched instance

Get the public ip

Fire putty, the login is typically ec2-user@IP

And add the ppk file like this
Login into the new machine

Get spark (https://spark.apache.org/

Untar

Enter the directory

Get private and public keys

And download them

Modifiy your ~/.bashrc

You need to copy the spark-test.pem into the ~/.ssh directory - winscp is your friend


./spark-ec2 -k spark-test -i ~/.ssh/spark-test.pem --hadoop-major-version=2 --spark-version=1.1.0 launch -s 1 ag-spark
 |
| Add caption |
If it does not work, Make sure that the region ( -r ) is the same of the key you have on your running machine
GO AND TAKE A COFFEE, the cluster is booting – it needs time.

Fire a browser and check the status
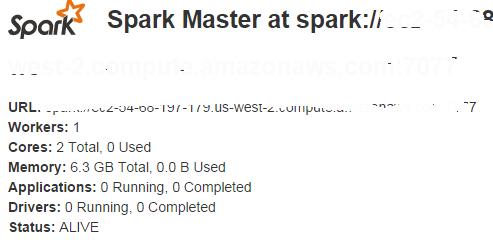
Login into the cluster

Subscribe to:
Posts (Atom)