Deep Learning is
a buzzword which entered the mainstream thanks to some recent results capturing
the attention of a global audience. Google’s Brain project learns to finds cats
in videos, Facebook recognizes faces in images, Baidu recognizes visual shapes
and objects, and both Baidu and Microsoft use deep learning for speech
recognition. Apart from buzzwords, the most prestigious minds are world-wide
working in deep learning including Jeff Dean (Google), Yann LeCun(Facebook),
Andrew Ng(Baidu).
One very
interesting progress made with Deep Learning is that it is now possible to
learn how to extract discriminative features in an automatic way. Instead,
traditional machine learning requires a lot of human effort for hand-crafting
features and the machine learning was essentially a way to learn weights for
balancing those features. Automatically discovering of discriminative features
is indeed a big step forward toward reasoning. Machines can now learn what is
important and what is not, while before humans had to pick features which were
potentially important and, then, let the machines weight them at the risk of
missing discriminative and fundamental information simply because it was not
considered. In short, we can say that now we have Trainable Feature Extractors
and Trainable Learning while before we only had the former. Auto-encoders are
one tool used by Deep Learning for finding features useful for representing an
input distribution.
Another
interesting characteristic of Deep Learning is the ability to learn from mostly
unlabelled data in a typical semi-supervised learning setting where a very
large number of training examples are not having complete and correct true
labels.
Yet another
interesting trait of Deep Learning is the ability to learn how to approximate
highly varying functions which happens when a piecewise approximation (with
constant or linear pieces) of a function requires a very large number of
pieces.
Deep learning
uses a cascade of many layers of non linear processing units which performs feature
extraction and transformation. What is still required is to compose manually the
layers according the specific problem to be solved. So, the big next step would
be to learn how to self-organize layers. Typically, Deep Learning compose many
(recurrent) layers of ANNs with even more sophisticated generative models such
as Deep Belief Networks and Deep Bolzmann Machines.
One fundamental
assumption is that each level will learn more abstract concepts of the previous
level. This concept is well explained in this image where the first layer
learns basic features, while the second layer learns components of human face,
and the third layer learns different types of faces. Hence, the learning system
is a high dimensional entity able to discriminate many observed features that
are related by unknown statistical relations. The learning is distributed in
the sense that the the knowledge itself is not associated with one single
neuron but it is the result of sharing the information within the network and
the consequent activation of multiple neurons.
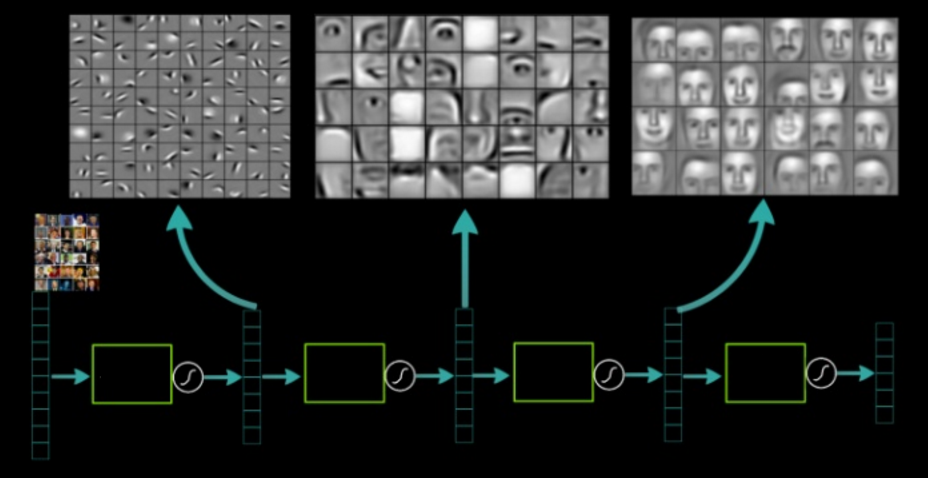
As shown in
this image, the features become more extended and complex deeper in the
network. In addition to that, multiple networks can be specialized on different
concepts and learn how faces, cars, elephants, and chairs are visualized.

Advances in
hardware have also been an important enabling factor for Deep Learning. In
particular, powerful graphics processing units (GPUs) are highly suited for
matrix and vector operations involved in machine learning and GPUs can speed up
training algorithms by orders of magnitude, bringing running times of weeks
back to few hours. This allows to increase the number of layers in a deep
network and therefore the level of sophistication in representing models. This
image gives another idea of how different levels are progressively learning
more and more complex visual features.

Deep Learning
network are typically trained via backpropagation where weights are updated via
Stochastic Gradient Descent using an equation such as

so that the
weight between the units
is updated at time
based on the weight available at time t plus a
fraction of the partial derivative of a chosen cost function.
is the learning rate. Google built an
Asynchronous Distributed Stochastic Gradient Descent server where more than 16000
CPUs independently update the gradient weights for learning the rather
sophisticate recognition of the concept of “cats” from a generic YouTube
video. Other types of training have been
proposed including forward propagation and forward-backward propagation for
Restricted Bolzmann Machines and for Recurrent Networks.
Another rather
sophisticate approach uses Convolutional networks (networks where the same
weight is used in all the spatial locations in the layer) with 24 layers for
annotating images with concepts showing an impressive 6.6% error rate at top 5
results, which is a result competitive with the human brain.[1]

Embedding is
another key concept introduced by Deep Learning. Embedding is used to avoid the
problems encountered when learning with sparse data. For instance, we can
extract words from documents and then create words embedding where words are
simply grouped together if they occur within a chosen text window. A word
embedding
: is a parameterized function
mapping words in some language to high-dimensional vectors (perhaps 200 to 500
dimensions). Embedding vectors trained for language modelling task have very
interesting proprieties where it is possible to express concepts and
equivalences such as the relations between capitals and countries, and the
relation between the queen and the king, and the meaning of superlative[2]
This table
describe a word embedding learned on a skip model trained on 783M words with
300 dimensionalities

If you are
interested in knowing more about Deep Learning, then it could be worth having a
look to a very exciting keynote by the way of Andrew Ng[3]. The
author of this book strongly believes that the next step for Deep Learning is
to integrate progress in HPC computation (where Spark is) with GPU computation
(where packages like Theano and Lasagne are). This will open the root on deep
learning cloud computation also leveraging the power of GPU platforms like
CUDA.[4]
No comments:
Post a Comment