Thursday, December 31, 2009
Sort a huge file
You are given a huge file with say 100 terabytes of integers. They don't fit in internal memory, what strategy would you use?
Wednesday, December 30, 2009
Selecting the median in an array
Ok, this is a typical "easy" interview question: you are given an array of integers, select the median value. What is the optimal solution?
Tuesday, December 29, 2009
A good tool for POS tagging, Named Entity recognition, and chunking,
YamCha is a good tool for POS tagging, Named Entity recognition, and chunking, based on SVM.
Monday, December 28, 2009
Introduction to Computational Advertising : Andrei Broder's course online
"Computational advertising is a new scientific discipline, at the intersection of information retrieval, machine learning, optimization, and microeconomics. Its central challenge is to find the best ad to present to a user engaged in a given context, such as querying a search engine ("sponsored search"), reading a web page ("content match"), watching a movie, and IM-ing. As such, Computational Advertising provides the foundations for building ad matching platforms that provide the technical infrastructure for the $20 billion industry of online advertising.
In this course we aim to provide an overview of the technology used in building online advertising platforms for various internet advertising formats."
Handsout of Andrei's course on Computatitional Advertising are now on line
In this course we aim to provide an overview of the technology used in building online advertising platforms for various internet advertising formats."
Handsout of Andrei's course on Computatitional Advertising are now on line
Sunday, December 27, 2009
KD-Tree: A C++ and Boost implementation
According to wikipedia a kd-tree (short for k-dimensional tree) is a space-partitioning data structure for organiizing points in a k-dimensional space. In this implementation, points are represented as a boost ublas matrix (numPoints x dimPoints) and the kd-tree can be seen as a row permutation of the matrix. The tree is built recursively. At depth k, the (k % dimPoints) coordinates are analyzed for all the points and the median of them is selected with a quickselect algorithm. The quickselection induces a natural row-index permutation for points in two sets, which are recursively partitioned on the next levels of the tree.
Here you have the code.
Here you have the code.
Saturday, December 26, 2009
Xmas present: Machine Learning: An Algorithmic Perspective
A very useful book for Machine Learning, with a lot of examples in python. Machine Learning: An Algorithmic Perspective is a must have in your library.
Friday, December 25, 2009
MultiArray: a useful container.
MultiArray is a useful boost container. Think about a hierarchical container which contains other containers. You can also have recursive definitions, where each level of the container can have other MultiArrays. Therefore a multi_array[float,2] is a matrix of float (dim=2), a multi_array[float,3] is a cuboid of float (dim =3). Instead, multi_array[multi_array[float,2], 3] is an object that you cannot represent with a 'simple' matrix: we are representing a cuboid where each cell is a matrix of floats.
MultiArrays can be accessed with the traditional iterator pattern, or accessed with the conventional bracket notation.
Maybe the most useful feature of MultiArray is the possibility to create views, where a subset of the underlying elements in a MultiArray as though it were a separate MultiArray.
MultiArrays can be accessed with the traditional iterator pattern, or accessed with the conventional bracket notation.
Maybe the most useful feature of MultiArray is the possibility to create views, where a subset of the underlying elements in a MultiArray as though it were a separate MultiArray.
Thursday, December 24, 2009
Building an HTTP proxy for filtering content
I am very agnostic for what is concerned programming languages.
C++ is a must for any production ready code, such as online search code (and if you use STL and boost you have a rich lib set). C# is useful for offline code, due to the inner rich set of lib set. Some people loves Java for this stuffs (e.g. Lucene, Hadoop, and other very good enviroment). Then, you you are in the scripting coding for fast and dirty prototyping you may want to use python (which is good for strong typed system) or perl (which is good for the vast set of modules, see CPAN).
So, I need to write an HTTP proxy for filtering some content. What is my choice? In this case, perl with HTTP::Proxy module, which allows me to filter both headers and content.
C++ is a must for any production ready code, such as online search code (and if you use STL and boost you have a rich lib set). C# is useful for offline code, due to the inner rich set of lib set. Some people loves Java for this stuffs (e.g. Lucene, Hadoop, and other very good enviroment). Then, you you are in the scripting coding for fast and dirty prototyping you may want to use python (which is good for strong typed system) or perl (which is good for the vast set of modules, see CPAN).
So, I need to write an HTTP proxy for filtering some content. What is my choice? In this case, perl with HTTP::Proxy module, which allows me to filter both headers and content.
Wednesday, December 23, 2009
A commodity vector space class
Sometime you need to realize a vectors space with dense vector. Here is a commodity class code.
PS: getting the sparse version is easy if you use Boost Ublas.
PS: getting the sparse version is easy if you use Boost Ublas.
Tuesday, December 22, 2009
Is this... the real 3D Mandelbrot then?
Fashinating article. Are fractals a form for search? In my opinion, Yes they are.
 "The original Mandelbrot is an amazing object that has captured the public's imagination for 30 years with its cascading patterns and hypnotically colorful detail. It's known as a 'fractal' - a type of shape that yields (sometimes elaborate) detail forever, no matter how far you 'zoom' into it (think of the trunk of a tree sprouting branches, which in turn split off into smaller branches, which themselves yield twigs etc.).
"The original Mandelbrot is an amazing object that has captured the public's imagination for 30 years with its cascading patterns and hypnotically colorful detail. It's known as a 'fractal' - a type of shape that yields (sometimes elaborate) detail forever, no matter how far you 'zoom' into it (think of the trunk of a tree sprouting branches, which in turn split off into smaller branches, which themselves yield twigs etc.).It's found by following a relatively simple math formula. But in the end, it's still only 2D and flat - there's no depth, shadows, perspective, or light sourcing. What we have featured in this article is a potential 3D version of the same fractal"
Monday, December 21, 2009
Facebook is growing big .. and I mean REALLY BIG!
Most Recent Facebook Common Stock Sale Values Company At $11 Billion, techcrunch reported. I already reported the Distribution of Facebook Users (~300M world wide). Anyway, what is really impressive is that FB is generating a lot of incoming traffic for many other web sites (you know when you embed some content). Very similar to what search engines are doing...
Sunday, December 20, 2009
Conditional Random Fields
Conditional Random Fields are a framework to build probabilistic models for segmenting
and labeling sequence data and are a valid alternative to HMMs. CRF++ is a valid package for computing CRF
and labeling sequence data and are a valid alternative to HMMs. CRF++ is a valid package for computing CRF
Saturday, December 19, 2009
Social, Mobile and the Local search
Ok, Google is going to buy yelp. Anyway, who cares about directories anymore? I am particularly impressed by the combination of Local, Social and Mobile. Oh yes, I meant foursquare. Check it out. I say real time search with a reason.
Friday, December 18, 2009
SAT and hill-climbing
SAT is a classifical NP problem, now what is the best known algorithm for building an approximate solution? WalkSAT
Pick a random unsatisfied clauses
Consider 3 moves; flipping each variable
If (any improve the evaluation)
{
accept the best
}
else
{
probability 0.5 : take the least bad
probability 0.5: pick a random move
}
Impressive no? and what this algorithm reminds to you?
Pick a random unsatisfied clauses
Consider 3 moves; flipping each variable
If (any improve the evaluation)
{
accept the best
}
else
{
probability 0.5 : take the least bad
probability 0.5: pick a random move
}
Impressive no? and what this algorithm reminds to you?
Thursday, December 17, 2009
Ellg: an open source social platform
I do encorauge to try elgg platform. Ok, it is in PhP which I don't like, but is cool and rich which I like. Consider that Facebook was written in PhP, after all.
Wednesday, December 16, 2009
Tuesday, December 15, 2009

Monday, December 14, 2009
Neural Networks and backpropagation
I am studying once again NN and back-propagation. Any paper out of there that compares standard grandient descend update rule (delta rule), with the one where you add a momentum?
Any other suggestions for different update rules?
Any other suggestions for different update rules?
Sunday, December 13, 2009
CTR and search engines
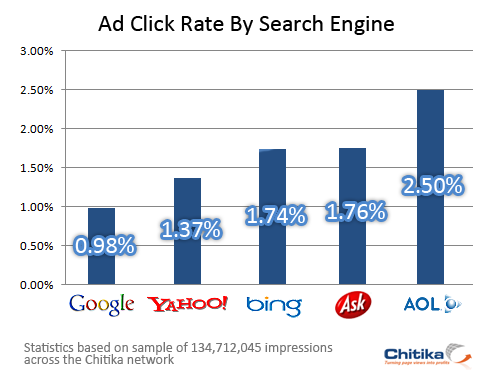 Chitka Research has released a report showing Bing users, the new search engine from Microsoft, clicking on ads 75% more often than Google users.
Chitka Research has released a report showing Bing users, the new search engine from Microsoft, clicking on ads 75% more often than Google users.Good sign? Ask and AOL has more CTR than bing
Saturday, December 12, 2009
Google: a usefult set of slides to build a distributed system
Designs, Lessons and Advice from Building Large Distributed Systems. Classical discussion about Map&Reduce and BigTable, plus an interesting overview about next incoming Snapper
Friday, December 11, 2009
Power Law and an Enrico Fermi's motivation
Power Laws are very frequent in data mining. For instance, you can find a power law in many properties of the web graph. I found a quite interesting explanation of power laws for modelling particles and cosmic radiation (Enrico Fermi 1949)
In this model, particles are produced at constant rate and the particles' distribution at time t is an exponential of the form \lamda * e ^ - (\lamda * t) (in other words there is a negative exponential contribution). In addition, particles gain energy when time is passing such as C e ^ (\alpha * t) (in other words this is giving a positive exponential contribution).
Under these two forces the particles will have a power law density. Can you explain why?
In this model, particles are produced at constant rate and the particles' distribution at time t is an exponential of the form \lamda * e ^ - (\lamda * t) (in other words there is a negative exponential contribution). In addition, particles gain energy when time is passing such as C e ^ (\alpha * t) (in other words this is giving a positive exponential contribution).
Under these two forces the particles will have a power law density. Can you explain why?
Thursday, December 10, 2009
Google is running fast on News (Please do not forget History)
I do have a lot of respect about the last Google's initiatives in News. "Living Stories" is a very cool prototype: "Today, on Google Labs, we're unveiling some of the work we've done in partnership with two world-class news organizations: The News York Times and The Washington Post. The result of that experiment is the Living Stories prototype, which features new ways to interact with news and the quality of reporting you've come to expect from the reporters and editors at The Post and The Times."
The key idea is that: "Each story has an evolving summary of current developments as a well as an interactive timeline of critical events. Stories can be explored by themes, significant participants or multimedia."
Google, I do like the idea of a collaboration with NYT and WP. Anyway, the idea of following the evolution of the story is not a new idea. It has been published in a patent Systems and methods for clustering information and used live by Ask.com as the 'History' feature:
"A clustering algorithm is used to cluster the information according to the selected window of time .omega.. New clusters can be periodically linked to chains, or new topic clusters can be identified, periodically. The new clusters are compared to other clusters to discover similarities in topic. When similarities are found among clusters in different time windows, the clusters are linked together to form a chain or are added to a preexisting chain. This comparison with clusters in previous time windows can stop if no similar information is found for a period of time proportional to the extension of the current cluster or to an extension of the chain. The chain of clusters is organized in a hierarchy according to the temporal information of each cluster: the most recent cluster is typically displayed at the top of the chain and the oldest cluster is typically displayed at the bottom of the chain."
On Feb 2008, this article gave a positive judgment about the 'History' feature: "My vote – thumbs up. Ask.com has done well integrating social media with news in a clean, easy-to-use interface. Features like story history could save me time"
The key idea is that: "Each story has an evolving summary of current developments as a well as an interactive timeline of critical events. Stories can be explored by themes, significant participants or multimedia."
Google, I do like the idea of a collaboration with NYT and WP. Anyway, the idea of following the evolution of the story is not a new idea. It has been published in a patent Systems and methods for clustering information and used live by Ask.com as the 'History' feature:
"A clustering algorithm is used to cluster the information according to the selected window of time .omega.. New clusters can be periodically linked to chains, or new topic clusters can be identified, periodically. The new clusters are compared to other clusters to discover similarities in topic. When similarities are found among clusters in different time windows, the clusters are linked together to form a chain or are added to a preexisting chain. This comparison with clusters in previous time windows can stop if no similar information is found for a period of time proportional to the extension of the current cluster or to an extension of the chain. The chain of clusters is organized in a hierarchy according to the temporal information of each cluster: the most recent cluster is typically displayed at the top of the chain and the oldest cluster is typically displayed at the bottom of the chain."
On Feb 2008, this article gave a positive judgment about the 'History' feature: "My vote – thumbs up. Ask.com has done well integrating social media with news in a clean, easy-to-use interface. Features like story history could save me time"
Wednesday, December 9, 2009
What are the zettabytes?
An interesting study about the information consumed in U.S.
"In 2008, Americans consumed information for about 1.3 trillion hours, an average of almost 12 hours per day. Consumption totaled 3.6 zettabytes and 10,845 trillion words, corresponding to 100,500 words and 34 gigabytes for an average person on an average day. A zettabyte is 10 to the 21st power bytes, a million million gigabytes. These estimates are from an analysis of more than 20 different sources of information, from very old (newspapers and books) to very new (portable computer games, satellite radio, and Internet video).
Video sources (moving pictures) dominate bytes of information, with 1.3 zettabytes from television and approximately 2 zettabytes of computer games. If hours or words are used
as the measurement, information sources are more widely distributed, with substantial amounts from radio, Internet browsing, and others. All of our results are estimates.
Previous studies of information have reported much lower quantities. Two previous How Much
Information? studies, by Peter Lyman and Hal Varian in 2000 and 2003, analyzed the quantity of original content created, rather than what was consumed. A more recent study measured consumption, but estimated that only .3 zettabytes were consumed worldwide in 2007.
Hours of information consumption grew at 2.6 percent per year from 1980 to 2008, due to a combination of population growth and increasing hours per capita, from 7.4 to 11.8. More surprising is that information consumption in bytes increased at only 5.4 percent per year. Yet the capacity to process data has been driven by Moore’s Law, rising at least 30 percent per year.
One reason for the slow growth in bytes is that color TV changed little over that period. High-definition TV is increasing the number of bytes in TV programs, but slowly.
The traditional media of radio and TV still dominate our consumption per day, with a total of 60 percent of the hours. In total, more than three-quarters of U.S. households’ information time is spent with noncomputer sources. Despite this, computers have had major effects on some aspects of information consumption. In the past, information consumption was overwhelmingly passive, with telephone being the only interactive medium.
Thanks to computers, a full third of words and more than half of bytes are now received interactively.
Reading, which was in decline due to the growth of television, tripled from 1980 to 2008, because it is theoverwhelmingly preferred way to receive words on the Internet."
"In 2008, Americans consumed information for about 1.3 trillion hours, an average of almost 12 hours per day. Consumption totaled 3.6 zettabytes and 10,845 trillion words, corresponding to 100,500 words and 34 gigabytes for an average person on an average day. A zettabyte is 10 to the 21st power bytes, a million million gigabytes. These estimates are from an analysis of more than 20 different sources of information, from very old (newspapers and books) to very new (portable computer games, satellite radio, and Internet video).
Video sources (moving pictures) dominate bytes of information, with 1.3 zettabytes from television and approximately 2 zettabytes of computer games. If hours or words are used
as the measurement, information sources are more widely distributed, with substantial amounts from radio, Internet browsing, and others. All of our results are estimates.
Previous studies of information have reported much lower quantities. Two previous How Much
Information? studies, by Peter Lyman and Hal Varian in 2000 and 2003, analyzed the quantity of original content created, rather than what was consumed. A more recent study measured consumption, but estimated that only .3 zettabytes were consumed worldwide in 2007.
Hours of information consumption grew at 2.6 percent per year from 1980 to 2008, due to a combination of population growth and increasing hours per capita, from 7.4 to 11.8. More surprising is that information consumption in bytes increased at only 5.4 percent per year. Yet the capacity to process data has been driven by Moore’s Law, rising at least 30 percent per year.
One reason for the slow growth in bytes is that color TV changed little over that period. High-definition TV is increasing the number of bytes in TV programs, but slowly.
The traditional media of radio and TV still dominate our consumption per day, with a total of 60 percent of the hours. In total, more than three-quarters of U.S. households’ information time is spent with noncomputer sources. Despite this, computers have had major effects on some aspects of information consumption. In the past, information consumption was overwhelmingly passive, with telephone being the only interactive medium.
Thanks to computers, a full third of words and more than half of bytes are now received interactively.
Reading, which was in decline due to the growth of television, tripled from 1980 to 2008, because it is theoverwhelmingly preferred way to receive words on the Internet."
Tuesday, December 8, 2009
Google is moving into Real-Time search
I am quite impressed of what google is doing in the real-time field, where they claim the monitor about 1 billion of fast moving urls.
Monday, December 7, 2009
Yahoo! and Microsoft cement 10-year search deal
Yahoo! and Microsoft have finalised the terms of their search agreement, five months after announcing the deal.
From The Telegraph
"Microsoft’s Bing and Yahoo! search are pooling their efforts in order to try and take on the dominance of Google in the search market. According to Net Applications’ most recent global figures, Google accounted for 85 per cent of all searches, while Bing took 3.3 per cent share and Yahoo! search accounted for 6.22 per cent of the total market. "
From The Telegraph
"Microsoft’s Bing and Yahoo! search are pooling their efforts in order to try and take on the dominance of Google in the search market. According to Net Applications’ most recent global figures, Google accounted for 85 per cent of all searches, while Bing took 3.3 per cent share and Yahoo! search accounted for 6.22 per cent of the total market. "
Sunday, December 6, 2009
Saturday, December 5, 2009
Dividing a number with no division
This could be an interview question, but do not expect me to ask this question anymore ;-)
"Given a>0 can you compute a^-1 without any division?"
"Given a>0 can you compute a^-1 without any division?"
Friday, December 4, 2009
Google Customizes More of Its Search Results
This is an important step for Google and I do appreciate the initiative. Personalized search has been one of the hot topic in the academia, with a lot of people trying to obtain a personalized version of page rank. Well, personalization is more about Dynamic ranking and not about Static ranking. Other search engines are also adopting personalized forms of ranking, but here google is raising the bar..
"For many of its users, Google offers Web search results that are customized based on their previous search history and clicks. For example, if someone consistently favors a particular sports site, Google will put that site high in the results when they look up sports topics in its search engine.
"For many of its users, Google offers Web search results that are customized based on their previous search history and clicks. For example, if someone consistently favors a particular sports site, Google will put that site high in the results when they look up sports topics in its search engine.
But there has always been one catch: people had to be signed in to a Google account to see such customization.
On Friday Google said it was extending these personalized search results to people who are not logged into the service."
Thursday, December 3, 2009
Quoting Wikipedia, which cites me and Alessio
This is a study that Alessio and me carried out back in 2004. Alessio is now Director of Search, Oneriot the Realt Time search engine beyond Yahoo!. Wikipedia is now citing us.
A more recent study, which used Web searches in 75 different languages to sample the Web, determined that there were over 11.5 billion Web pages in the publicly indexable Web as of the end of January 2005.[61]
A more recent study, which used Web searches in 75 different languages to sample the Web, determined that there were over 11.5 billion Web pages in the publicly indexable Web as of the end of January 2005.[61]
Wednesday, December 2, 2009
Search capitalization

This is a one year comparison about market capitalization on 1 Dec 2009. I used Apple as benchmark since that tech stock had a great performance this year.
Tuesday, December 1, 2009
Web Search signals
Search Engine Watch just published an article about 'new' search signals. Well, I don't believe these are new signals since they are quite well discussed in already published seach patents (seo by the sea is a great source for search patents). In addition, query session data analysis is missing in the list and that is another very important class of signals.
Subscribe to:
Posts (Atom)