How to minimize the quadratic function f(x) = 1/2 x^T A x + b^T x + c, subject to the constrain Vx=d, where T is the usual transpose operator, A is a matrix, and b, c, d are vectors?
Pretty elegant application of Karush–Kuhn–Tucker conditions
Monday, November 30, 2009
Sunday, November 29, 2009
Vivisimo, SnakeT, Ask, Bing and now Google side bar
Vivisimo and SnakeT experimented with it. Bing made it for real. Ask3d proposed it and then left to become more Google like. Now google wants to be similar to Ask3d and Bing. Quoting pandia. Life is a circle. In any case, the Categorized search with automatically generated sidebar proposal was an important part of my Ph.D thesis, back in 2004-2005. This is about being a bit early than others. SnakeT is no longer maintained but still working back from the university days.
"Unlike Bing and Yahoo, Google does not have a permanent left hand sidebar with additional links for more narrow searches. Instead there is a link at the top of the page called “Show options”.
Click on it and Google will add a sidebar which helps you refine your search query. You may, for instance, limit your search to new pages from the last hour.
Search Engine Land reports that Google will change it’s search result pages next year and give them a more coherent look and feel.
Most importantly: It seems the sidebar will become a permanent feature on all search result pages.

The sidebar will include links to Images, News, Books, Maps and “More”, as well as related searches and links that let you limit the search to a specific time period.
Google will give you the alternatives (or “modes”) it thinks is most relevant to your search.
Ask.com launched search result pages like this in 2007. Because of this Ask.com became one of our favorite search engines. Ask later abandoned its “3D” search in order to become more like Google!"
Saturday, November 28, 2009
I will give a talk at Online Information 2009
Here you have the details of my invited talk: "The realtime web: Discovery vs. Search"
Friday, November 27, 2009
When you want to optimize the monetization...
Not the parameter for a search engine. Great article from Danny.
Thursday, November 26, 2009
Search Layers
Search Engines tend to organize indexes in layers. The intuition is that: If "enough good" documents are retrieved from the i-th layer, then you don't need to go to the (i+1)-th layer. Questions:
1. how do you partition the documents?
2. what is "good"?
3. what is "enough"?
Please formalize your answers.
1. how do you partition the documents?
2. what is "good"?
3. what is "enough"?
Please formalize your answers.
Wednesday, November 25, 2009
Distribution of Facebook Users (~300M world wide)

Facebook claims that they have more than 300 Million of users world wide. I sampled their ads user database and found the following geographical users' distribution:
- 34.32% are in U.S.
- 8.15% are in U.K.
- 5.05% are in France
- 4.99% are in Canada
- 4.50% are in Italy
- 4.42% are in Indonesia
- 2.65% are in Spain
Tuesday, November 24, 2009
Monday, November 23, 2009
Weights and Scale: a variation.
You have 6 weights which appears almost identical but 3 of them are slightly heavier than the remaining 3. The 6 weigth have 3 colours: red, green and blue. For each colour there is a pair of weights and one of the weight in the pair is slighlty heavier than the other. How many times do you need to use a scale with two plates for identifying the lighter weights?
Sunday, November 22, 2009
Ranking teams
Suppose that you have N teams playing a football league. Each team has a rank r_i parameter> 0 and assume there are no ties. Questions:
- What is the probability for team i to win on team j?
- What is the probability of the whole season (each team plays against the remaining ones)?
- Find an algorithm to rank the teams
Saturday, November 21, 2009
Random Decision Trees
Random Decision Trees are an interesting variant of Decision Trees. Here the key elements:
- Different training sets are generated from the N objects in the original training set, by using a bootstrap procedure which randomly samples the same example multiple times. Each sample generate a different tree and all the trees are seen as a forest;
- The random trees classifier takes the input feature vector, classifies it with every tree in the forest, and outputs the class label that recieved the majority of “votes”.
- Each node of each tree is trained on a random subset of the variables. The size of this set is a training parameter (in general sqrt(#features)). The best split criterium is chosen just considering the random sampled variables;
- Due to the above random selection, some training elements are left out for evaluation. In particular, for each left-out vector, find the the class that has got the majority of votes in the trees and compare it to the ground-truth response.
- Classification error estimate is computed as ratio of number of misclassified left-out vectors to all the vectors in the original data.
Friday, November 20, 2009
Bing UK -- Out Of Beta Tag For Handling Search Overload In The UK
Nice article here
It is true that Internet has drastically grown in the past few years and has become more complex, but Search Engines are still on the verge of evolution. In order to make search engines more reliable information resource for users, Microsoft launched Bing in June, 2009.
Bing was launched under Beta tag in the UK. Microsoft at that time promised to remove the tag only under one condition i.e if its experience would be different from the competition and if the results would be outperforming in terms of UK relevancy.
The Bing team reached its objective on November 12, 2009 and the credit goes to London-based Search Technology Center. Microsoft says that 60 engineers behind the project in Soho have done extensive job at localizing the Bing global experience for the UK users in just 5 months.
It is true that Internet has drastically grown in the past few years and has become more complex, but Search Engines are still on the verge of evolution. In order to make search engines more reliable information resource for users, Microsoft launched Bing in June, 2009.
Bing was launched under Beta tag in the UK. Microsoft at that time promised to remove the tag only under one condition i.e if its experience would be different from the competition and if the results would be outperforming in terms of UK relevancy.
The Bing team reached its objective on November 12, 2009 and the credit goes to London-based Search Technology Center. Microsoft says that 60 engineers behind the project in Soho have done extensive job at localizing the Bing global experience for the UK users in just 5 months.
Thursday, November 19, 2009
Is this the future of Search?
The word search is never mentioned in this video, but what this guy just about Visual Searching. Is this our future? This is going to be open-source and the current cost is 300 dollar.
WOW.
WOW.
Scaling Internet Search Engines: Methods and Analysis
A great Ph.d. thesis to read if you are interested in search engine architecture. The main focus is how to build scalable indexes distributed on thousand of search nodes. A lot of low level details such as building inverted indexes, suffix arrays, distributed caching systems, query optimization, etc.
This technology has been adopted by Fast and later on by Yahoo.
This technology has been adopted by Fast and later on by Yahoo.
Wednesday, November 18, 2009
Visual Studio and Parallel computation
Visual Studio 2010 Beta 2 added an extensive support for parallel (multi-core) computation, with an impressive debugger and profiler. This article gives a good introduction.
Tuesday, November 17, 2009
Bing Gains Another Half Point Of Search Share In October
- During October, Bing represented 9.9% of the market, up from 9.4% in September, according to comScore.
- Yahoo got slammed, losing almost a full percentage point of the market, to 18.0%, down from 18.8% in September.
- Google gained a bit of share, to 65.4% in October, up from 64.9% in September.
Total search volume increased 13.2% in October, below 17.3% growth in September.
More information here
Monday, November 16, 2009
Bing - Out Of Beta Tag For Handling Search Overload In The UK
"The Bing team reached its objective on November 12, 2009 and the credit goes to London-based Search Technology Center. Microsoft says that 60 engineers behind the project in Soho have done extensive job at localizing the Bing global experience for the UK users in just 5 months. The team worked under the direction of Jordi Ribas' has done a miraculous job by crunching historical algorithmic results for identifying local intents and including them in the Bing's categorized search."
More information here
More information here
Sunday, November 15, 2009
A collection of benchmarks for Learning to Rank algorithms
This is very useful if you are into Learning to Rank methodologies.
Saturday, November 14, 2009
Directly Optimizing Evaluation Measures in Learning to Rank
Directly Optimizing Evaluation Measures in Learning to Rank
"Experimental results show thatthe methods based on direct optimization of evaluation measure scan always outperform conventional methods of Ranking SVM andRankBoost. However, no significant di fference exists among the performances of the direct optimization methods themselves."
In this case, my preference goes to AdaRank for its semplicity and clear understanding of the key intuitions behind it.
"Experimental results show thatthe methods based on direct optimization of evaluation measure scan always outperform conventional methods of Ranking SVM andRankBoost. However, no significant di fference exists among the performances of the direct optimization methods themselves."
In this case, my preference goes to AdaRank for its semplicity and clear understanding of the key intuitions behind it.
Friday, November 13, 2009
A taxonomy of classifiers
I found this taxonomy of classifiers useful:
Classifiers are generally combined in an Ensembles of classifiers. Many of the above methods are implemented in OpenCV
- Statistical
- Regression (linear), (logistic)
- Structural
- Rule Based (production rules, decision tree, boosting DT, Random Forest)
- Neural Network
- Support Vector Machine
- Distance Based
- Functional (linear, wavelet)
- Nearest Neighbor (kNN, Learning Vector Quantization, Self-organizing maps)
Classifiers are generally combined in an Ensembles of classifiers. Many of the above methods are implemented in OpenCV
Thursday, November 12, 2009
A collection of public works on Learning to Rank from Microsoft
Nowadays, Learning to Rank is a quite popular subject. Search engines are no longer using only convential Random Walks on web graphs (e.g. PageRank and similar algos), but they learn from past user queries and clicks. This is a collection of recent public works @ Microsoft:
- RankNet [2005]
- LambdaRank [2006-2009], works directly on optimizing DCG
- BoostTreeRank [2006], ranking as a classification problem and uses boosting
- LamdbaMart [2009], which combines the above with boosting, regression trees and allows to have submodels
Wednesday, November 11, 2009
GO a new language from Google
Go is a new language from Google. Robert Pike and Ken Thompson are behind it. (I believe they are Godness for programmer ;-). At first glance, Go stays in the middle between C++ and Python.
I am trying to understand a bit more about the language. Garbage collection is there, type inference is there, lamba/closure is there, but where are modern things like generic/collections and exceptions?
Generic is a commonly accepted programming paradigm that any modern programmer is using (C++ has it, Java has it, etc, etc?)
BTW, there was already a programming language called Go and google missed it ?
I am trying to understand a bit more about the language. Garbage collection is there, type inference is there, lamba/closure is there, but where are modern things like generic/collections and exceptions?
Generic is a commonly accepted programming paradigm that any modern programmer is using (C++ has it, Java has it, etc, etc?)
BTW, there was already a programming language called Go and google missed it ?
Tuesday, November 10, 2009
Reoder an array in mimum number of steps
You have the array 876501234. The numbers on the right of the 0 are given in ascending order (1234), the numbers on the left of the zero are given in descending order (8765). 0 is an empty position. A number can move either in an adjacent empty position, or it can jump one single number and land in an empty position. Number cannot "move back" (e.g. the ascending number can just move from right to the left, the descending viceversa). You want to get the array 123408765, with the minimum number of moves.
Monday, November 9, 2009
DBSCAN clustering algorithm
DBSCAN is a well-known clustering algorithm, which is easy to implement. Quoting Wikipedia: "Basically, a point q is directly density-reachable from a point p if it is not farther away than a given distance ε (i.e., is part of its ε-neighborhood), and if p is surrounded by sufficiently many points such that one may consider p and q be part of a cluster.... For practical considerations, the time complexity is mostly governed by the number of getNeighbors queries. DBSCAN executes exactly one such query for each point, and if an indexing structure is used that executes such a neighborhood query in O(logn), an overall runtime complexity of 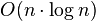 is obtained."
is obtained."
Some DBSCAN advantages:
Here you have a DBSCAN code implemented in C++, boost and stl
is obtained."Some DBSCAN advantages:
- DBScan does not require you to know the number of clusters in the data a priori, as opposed to k-means.
- DBScan can find arbitrarily shaped clusters.
- DBScan has a notion of noise.
- DBScan requires just two parameters and is mostly insensitive to the ordering of the points in the database
- DBScan needs to materialize the distance matrix for finding the neighbords. It has a complexity of O((n2-n)/2) since only an upper matrix is needed. Within the distance matrix the nearest neighbors can be detected by selecting a tuple with minimums functions over the rows and columns. Databases solve the neighborhood problem with indexes specifically designed for this type of application. For large scale applications, you cannot afford to materialize the distance matrix
- Finding neighbords is an operation based on distance (generally the Euclidean distance) and the algorithm may find the curse of dimensionality problem
Here you have a DBSCAN code implemented in C++, boost and stl
Sunday, November 8, 2009
Invalidating iterators
If you use iterators to access a std::vector, can you modify the vector? Surprisingly enough a lot of C++ programmers do not know the answer to this question. Therefore, they don't know how to avoid the problem of invalidating iterators. What about you?
Saturday, November 7, 2009
A tutorial on static polymorphism
A good tutorial for template-based “compile-time polymorphism" . It shows how the technique can compete with traditional run-time polymorphism, and how the two can work together.
Friday, November 6, 2009
Thursday, November 5, 2009
C++ Polymorphism., static or dynamic inheritance (part II)
Just a little extension of the previous posting about static polymorphism . Here, I define two different types of distances:
Here the code
- Distance euclidean d
- Distance cosine d
Here the code
Wednesday, November 4, 2009
Tuesday, November 3, 2009
C++ Polymorphism., static or dynamic inheritance
Traditional C++ programmers are used to think that everything should be modelled as a collection of classes and objects, organized in a hierarchy.
Inheriting is a great thing, but sometime you don't want to pay the overhead of a virtual method. I mean, anytime you overide a method the compiler will add a new entry in the virtual table and at run-time a pointer must be deferenced. When performance is crucial or when you call a method several times in your code you may want to save this cost.
In these situations, Modern C++ programmers prefer to adop a kind of compile-time variant of the strategy pattern. At compile time, the appropriate class and method is called during template instatiation. In this sense, Policy-based design is very useful when you want to save the cost of the virtual table.
In this example, I wrote a distance class and a method distance which is potentially used very frequently by any clustering algorithm. The method can be either a EuclideanDistance, or any kind of different distance. And there is no need of any additional virtual table, every choice is made at compile time statically.
Here you find the code.
Inheriting is a great thing, but sometime you don't want to pay the overhead of a virtual method. I mean, anytime you overide a method the compiler will add a new entry in the virtual table and at run-time a pointer must be deferenced. When performance is crucial or when you call a method several times in your code you may want to save this cost.
In these situations, Modern C++ programmers prefer to adop a kind of compile-time variant of the strategy pattern. At compile time, the appropriate class and method is called during template instatiation. In this sense, Policy-based design is very useful when you want to save the cost of the virtual table.
In this example, I wrote a distance class and a method distance which is potentially used very frequently by any clustering algorithm. The method can be either a EuclideanDistance, or any kind of different distance. And there is no need of any additional virtual table, every choice is made at compile time statically.
Here you find the code.
Monday, November 2, 2009
Where Google is going with Enterprise, Real time and other stuff
An interesting interview to Eric Schmidt, it's worth listening it several times ;-)
Sunday, November 1, 2009
Can Google Stay on Top of the Web?
Worth reading.
1. Microsoft's (MSFT) new Bing search engine picked up 1.5 percentage points of market share in August to hit 9.5%, according to market researcher Hitwise, while Google's share fell from 71.4% to 70.2%.
2. But longer term, Twitter, Facebook, and related services may pose a more fundamental threat to Google: a new center of the Internet universe outside of search. Twitter, now with 55 million monthly visitors, and Facebook, with 300 million, hint at an emerging Web in which people don't merely read or watch material but communicate, collaborate with colleagues, and otherwise get things done using online services.
3. Meanwhile, Google's very success and size are starting to work against it. In the past year the company has been the target of three U.S. antitrust inquiries and one in Italy. Most recently the Justice Dept. on Sept. 18 said Google's controversial settlement with authors and publishers, which would have allowed it to scan and sell certain books, must be changed to avoid breaking antitrust laws. Even Google's own paying customers—advertisers and ad agencies—say they're eager for alternatives to blunt Google's power. Says Roger Barnette, president of search marketing firm SearchIgnite: "People want a No. 2 that has heft and scale."
4. Most of the search quality group's contributions are less visible because its work is focused mostly on the underlying algorithms, the mathematical formulas that determine which results appear in response to a particular query. Google conducts some 5,000 experiments annually on those formulas and makes up to 500 changes a year
1. Microsoft's (MSFT) new Bing search engine picked up 1.5 percentage points of market share in August to hit 9.5%, according to market researcher Hitwise, while Google's share fell from 71.4% to 70.2%.
2. But longer term, Twitter, Facebook, and related services may pose a more fundamental threat to Google: a new center of the Internet universe outside of search. Twitter, now with 55 million monthly visitors, and Facebook, with 300 million, hint at an emerging Web in which people don't merely read or watch material but communicate, collaborate with colleagues, and otherwise get things done using online services.
3. Meanwhile, Google's very success and size are starting to work against it. In the past year the company has been the target of three U.S. antitrust inquiries and one in Italy. Most recently the Justice Dept. on Sept. 18 said Google's controversial settlement with authors and publishers, which would have allowed it to scan and sell certain books, must be changed to avoid breaking antitrust laws. Even Google's own paying customers—advertisers and ad agencies—say they're eager for alternatives to blunt Google's power. Says Roger Barnette, president of search marketing firm SearchIgnite: "People want a No. 2 that has heft and scale."
4. Most of the search quality group's contributions are less visible because its work is focused mostly on the underlying algorithms, the mathematical formulas that determine which results appear in response to a particular query. Google conducts some 5,000 experiments annually on those formulas and makes up to 500 changes a year
Subscribe to:
Posts (Atom)